
相信大家在平时使用电脑的时候一定都碰到过乱码的问题,无论是打开txt文件后满屏的“锟斤拷",还是命令行里的“烫烫烫",这些问题的产生都与字符编码密切相关。
基本概念
字符:在计算机中,一个字符是一个单位的字形、类字形单位或符号的基本信息。一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号都是一个字符。
字符集:多个字符的集合。计算机种的字符集是指已编号的字符的有序集合,常见字符集有ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。
码点:指在某个字符集当中,所有字符有序编号后的编号空间中的一个位置,就叫做码点(Code Point)。通常混用码点与码点值。需要注意的是,Unicode中一个字符可能与多个码点对应。
字符编码:字符编码是一种映射规则,根据这个规则可以把字符集中的每个字符的码点转换为有限长度的编码值,方便在计算机中存储和传输。
字符集和字符编码的关系 :
通常特定的字符集采用特定的编码方式,也就是一种字符集对应一种字符编码,比如ASCII、GB2312、GBK等都是同时代表字符集和对应的字符编码,可以归为传统字符编码模型。
以Unicode为代表的现代字符编码模型中,可以采用不同的编码方式来对同一个字符集进行编码,也就是这时字符集与字符编码之间是一对多的关系。
为什么要有字符编码
字符或文字,对于人来说是很容易识别的,但问题在于计算机一个都不认识。计算机只认识0或者1,所以为了能够使用计算机处理文本,我们就必须建立一套编码规则,使得每一个字符都能够对应一个唯一的0和1组成的数字。比如01000001对应字母'A',01000010对应字母'B',以此类推。
计算机处理信息的基本单位是字节,一个字节由8位二进制数组成,也就是有256种可能性。对于英文体系来说,只需要编码26个英文字符和一些标点特殊符号就可以,甚至都不需要用到8位,7位128种编码就已经足够了。这也就是最基础和应用最广的ASCII编码。
英文语系编码
ASCII码
ASCII码(American Standard Code for Information Interchange美国信息交换标准码),由美国国家标准学会ANSI(American National Standard Institute)在1967年第一次作为规范标准发表,后来被国际标准化组织(ISO)定为国际标准ISO/IEC 646。
目前常见的各种字符编码一般都直接或者间接兼容ASCII编码,比如ISO-8859,GB2312,GBK,Big5和 Unicode等。
ASCII字符集中一共有128个字符,码点范围从0到127,所以只占用了一个字节的低位7个比特,剩下的最高位比特记为0。如下表所示。
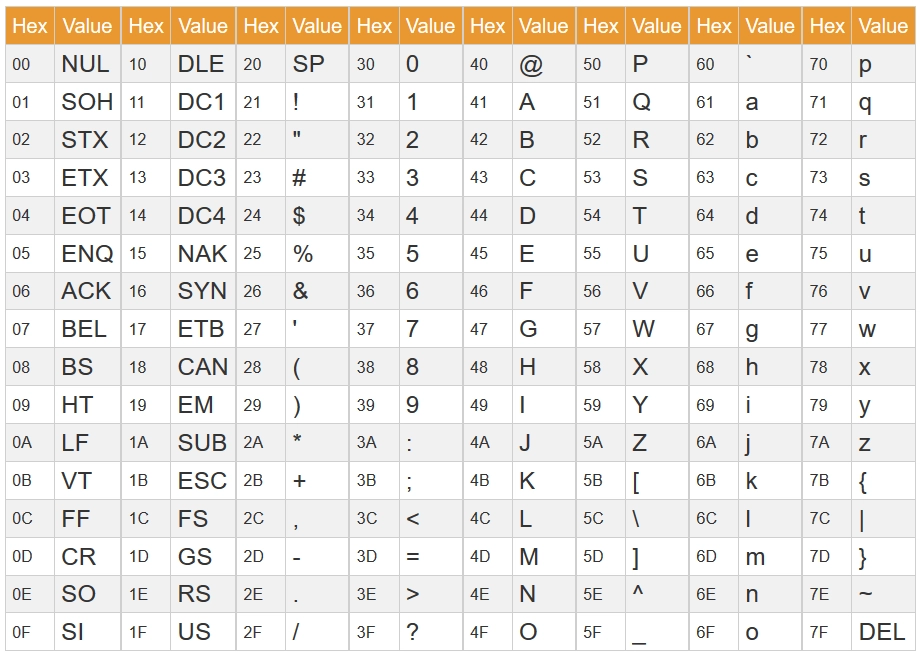
在128个字符中,可以按照类型做划分:
- 0~31:控制字符或不可见字符,比如0x00代表Null,一般用于指示字符串结尾,0x0A(LF,Line Feed)用来表示换行等。
- 32~126:可以显示和打印的字符,比如0x30~0x39是阿拉伯数字1-9,0x41~0x5A是26个大写英文字母,0x61~0x7a是26个小写英文字母
- 127:控制字符DEL
这种编码十分简单,在保存到计算机中时,也只需要把码点转为一个二进制字节写入就可以,比如A对应0x41,转为二进制就是01000001。
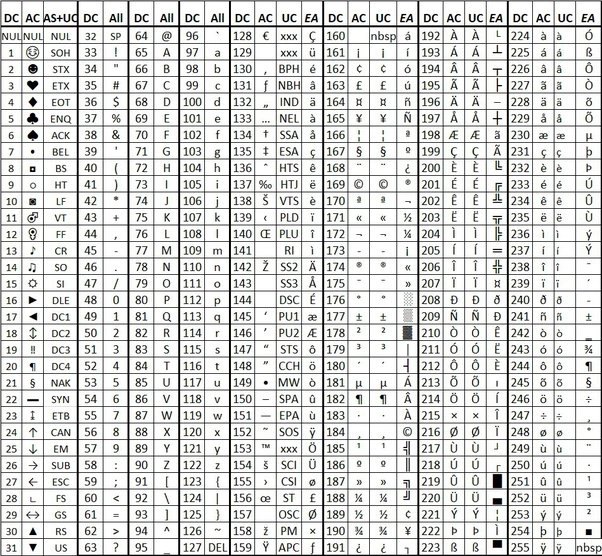
EASCII码
ASCII码对于美国使用已经足够了,但当计算机在欧洲流行时,人们发现有很多欧洲特有的字符并不包含在其中,需要进行扩展。一个字节可以表示256种编码,但ASCII实际上只用到了低7位的比特,所以还留有128个编码可以用来扩展,于是就产生了扩展ASCII码(Extended ASCII)。
在EASCII码中,前128个字符与ASCII码相同,保证了对ASCII码的兼容性,后128个字符扩展里新的希腊字母、拉丁符号、表格符号等,如下表所示。
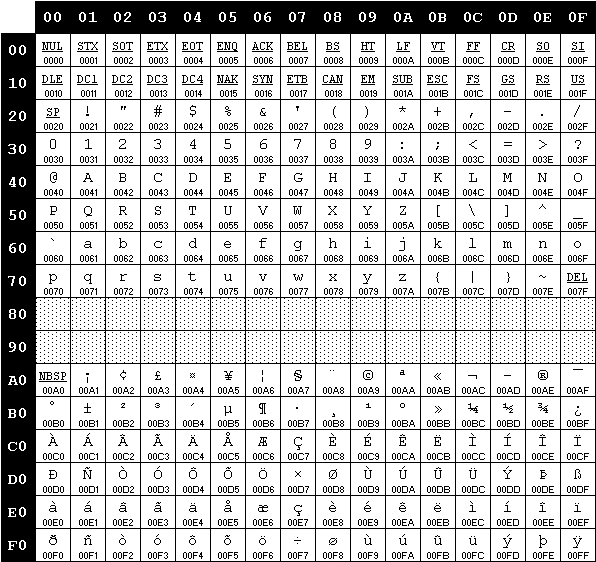
ISO/IEC 8859字符集
ISO/IEC 8859是一系列的字符集的总称,除了已经废弃的ISO/IEC 8859-12,一共包括15个字符集。ISO/IEC 8859-1目前使用的最为普遍,一般也叫ISO 8859-1,或者叫Latin-1(Latin1)。如下图所示。
完整的ISO/IEC 8859字符集系列如下:
- ISO/IEC 8859-1 (Latin-1) - 西欧语言
- ISO/IEC 8859-2 (Latin-2) - 中欧语言
- ISO/IEC 8859-3 (Latin-3) - 南欧语言。世界语也可用此字符集显示。
- ISO/IEC 8859-4 (Latin-4) - 北欧语言
- ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
- ISO/IEC 8859-6 (Arabic) - 阿拉伯语
- ISO/IEC 8859-7 (Greek) - 希腊语
- ISO/IEC 8859-8 (Hebrew) - 希伯来语(视觉顺序)
- ISO 8859-8-I - 希伯来语(逻辑顺序)
- ISO/IEC 8859-9(Latin-5 或 Turkish)- 它把Latin-1的冰岛语字母换走,加入土耳其语字母。
- ISO/IEC 8859-10(Latin-6 或 Nordic)- 北日耳曼语支,用来代替Latin-4。
- ISO/IEC 8859-11 (Thai) - 泰语,从泰国的 TIS620 标准字集演化而来。
- ISO/IEC 8859-13(Latin-7 或 Baltic Rim)- 波罗的语族
- ISO/IEC 8859-14(Latin-8 或 Celtic)- 凯尔特语族
- ISO/IEC 8859-15 (Latin-9) - 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。
- ISO/IEC 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
汉字 东亚语言编码
英文字母加上各种常见标点符号、控制字符之类的再怎么扩展,一个字节也足够使用了(2^8=256种可能)。但当计算机发展到中国时,事情就不一样了,比如中文的汉字多达近10万个,即使是只统计最常用的也有几千个,一个字节显然远远不足,因此必须使用多个字节来表示一个字符。
GB2312
GB 2312全称《信息交换用汉字编码字符集·基本集》,GB也就是国标汉字拼音简写,由中国国家标准总局在1980年发布。GB 2312一共收录了6763个汉字,以及包括拉丁字母、希腊字母、日文片假名等在内的682个字符。
为了能够兼容ASCII码,GB2312采用双字节编码,同时规定一个汉字的编码的必须是由两个大于127的字节组成。这样如果一个字节的值小于127(也就是字节的最高位为0),那就表示是ASCII字符。
GB 2312对汉字进行了分区处理,将所有字符分为了94个区,每个区含有94个汉字或符号。每个汉字或字符都对应了一个分区编号和分区内的位置编号,这就是该字符的区位码。比如汉字"中"在第54区的48号,那么“中”字的区位码就是54-48。
当我们有了汉字的区位码后,还不能直接保存到电脑中,因为显而易见即使最大的区位码94-94,如果直接保存为两个字节,每个字节都会小于127,和我们刚才规定的ASCII码兼容规则冲突。因此规定将区位码的每个位置分别加上160,作为内码保存,比如“中"字,区位码是54-48,分别加上160就是214-208,对应16进制也就是d6 d0。
GB 2312中对一些ASCII码中就有的符号使用两个字节也进行了编码,而且这些符号在显示宽度上与汉字相同,这些字符就叫全角字符。相对的,原本ASCII中的对应字符由于显示宽度只有半个汉字,而且是一个字节编码,叫半角字符。
GBK
GBK 全称《汉字内码扩展规范(GBK)》1.0版,一共收录了21886个汉字和图形符号,其中汉字21003个,符号883个。GBK是“国家标准扩展”的汉语拼音简写。
与GB 2312相同,GBK也是双字节编码,而且为了兼容GB 2312,GBK使用GB 2312中没有用到的编码区进行了扩展,第一个字节的范围是0x81-0xFE,第二个字节的范围是0x40-0xFE。容易看出,GBK中的第二个字节是可能小于128的,所以在读取时,如果遇到一个字节的开头是1,标明该字节和随后的一个字节共同表示一个汉字。
GB 18030
GB 18030全称《信息技术 中文编码字符集》,向后兼容GBK、GB 2312和ASCII码。截止最新标准GB 18030-2022,一共收录了87887个汉字汉字和部首228个。
不同于GBK,GB 18030采用的是变长多字节编码,类似于UTF-8,每个字可以由1个、2个或者4个字节组成。GB 18030的编码规则比较复杂,这里不做过多解释,有兴趣的朋友可以自行搜索相关技术规范。
ANSI
正如前面所述,不同的国家都制定了各自不同的字符集和编码,这些编码一般都兼容ASCII码,但互相之间基本都不兼容。有时我们使用软件时,会看到一种叫ANSI的编码,在不同的系统中,ANSI指代了不同的字符编码,比如在简体中文windows系统中代表GBK或者GB 18030编码,在繁体中文系统中代表BIG5编码等。
ANSI中规定,简体中文GB编码的代码页是936,打开终端使用chcp命令我们就可以查询到当前使用的代码页。代码页是字符编码的别名,也叫内码表,是特定语言的字符集的一张表,用来字符在计算机中的存储和显示。比如当我们读取到了一个或多个字节,系统就会根据当前的设置去对应的代码页查询如何进行字符显示。
由于ANSI在不同语言的系统中代表了不同的编码,所以如果将一个中文系统中的ANSI编码文件发送到英文系统中用ANSI编码打开,乱码自然就产生了,因为二者对于相同字节应该显示的字符是不一样的,除了都兼容的ASCII码内的字符。
Unicode
Unicode字符集
刚才有提到,随着计算机的发展,各个国家和地区搞出来了一堆兼容ASCII但又互不兼容的字符集和编码方案,也带来了各式各样的乱码问题,那么为什么不发明一个超级大的字符集把世界上所有的字符都包含在内呢。于是,Unicode字符集诞生了。
Unicode全称为Unicode标准,中文名统一码或者万国码。截止最新版本,已经收录了超过14万个字符,而且还在不断的增修当中。Unicode被ISO纳入为国际标准ISO/IEC 10640,被目前的计算机系统应用。
如此多的字符,自然要做一些分类,Unicode将所有的字符根据书写系统划分为了0~16一共17个区,也叫平面,每个平面有65536(2^16)个字符,目前第4号到第13号平面都未启用。第0号平面,最前面的65536个字符位,被称作基本平面(Basic Multilingual Plane,BMP),包含了最常用的字符。
Unicode给每一个字符分配了唯一的码点值,用U+对应码点值的十六进制数的方式表示,比如U+0041就是大写字母A。
Unicode编码 UTF-32
在简单字符集方案中,一般一个字符集只有一种字符编码方式,但到了Unicode事情变得不太一样了。比如汉字的“汉",Unicode码点是0x6c49,二进制0110110001001001,需要最少两个字节表示,而更大的码点值还需要更多的字节。可能有人立即想到那我直接统一规定所有的字符都用4个字节表示不就可以了,这就是UTF-32。
UTF-32的每个码点用四个字节表示,字节内容和码点值一一对应,不需要额外的转换。比如,码点U+0041就是低位两个字节是0x0041,然后前面再加两个字节的0,也就是0x0000 0041。UTF-32的转换规则简单直观,但也有一个致命的缺点,占用了过多的空间。比如对于一篇全是英文字母的小说,使用ASCII编码,每个字母只需要一个字节,而UTF-32编码需要4个字节,也就是需要占用四倍的硬盘空间。
由于UTF-32占用过多空间的缺点,目前其很少被使用
UTF-16编码
UTF-16编码是UCS-2编码的超集(JavaScript就默认使用UCS-2编码),这是一种变长的编码方案,规定基本平面的字符占用2个字节,辅助平面的字符占用4个字节。但问题来了,当我们读取一个UTF-16编码的文件时,怎么知道接下来的两个字节是1个字符还是要继续读取两个字节组成1个字符呢?
在基本平面中,从U+D800到U+DFFF一共2^11个位置是空的,这些码点不对应任何字符,UTF-16就巧妙的运用这个空段进行了字符映射。辅助平面的字符一共有2^20个,也就是需要最少20个二进制位。将这20个二进制位分为两半,其中前十位映射到U+D800-U+DBFF,称作高位,后十位映射到U+DC00-U+DFFF,称作低位。这时,只要两个字节在U+D800到U+DBFF范围内,就说明还需要再读取两个字节,共同组成一个字符。
比如对于汉字"𠮷",其Unicode码点值为U+20BB7,超出了基本平面的范围,需要进行转换。用0x20BB7-0x10000计算超出的部分,结果为0x042 0x3B7,将高位的10比特的值0x042加上0xD800,结果为0xD842,将低位的10比特的值0x3B7加上0xDC00,结果为0xDFB7,所以其UTF-16编码为0xD842 0xDFB7。
得到了编码,还需要考虑字节序的问题,在计算机中有两种字节序,大端序和小端序。其中小端序是指将低位字节放在内存的低地址,高位字节放在内存的高地址,而大端序正好相反。比如0x1234567的大端序存储方式从内存低地址到高地址是0x01 0x23 0x45 0x67,而小端序则是0x67 0x45 0x23 0x01。
为了区分不同的字节序,Unicode推荐在文件开头添加几个特殊字节来标记字节序,叫做BOM(Byte Order Mark)。对于UTF-16,如果接收到前两个字节是0xFE 0xFF,就标明文件是大端序,而如果是0xFF 0xFE,说明是小端序。当我们在一个文件中写入了汉字"𠮷",同时添加BOM,如果是大端序,那么文件内容就是0xFE 0xFF 0xD8 0x42 0xDF 0xB7,如果是小端序,则是0xFF 0xFE 0x42 0xD8 0xB7 0xDF。
UTF-8编码
使用UTF-16变长编码,我们在一定程度上解决了UTF-32的空间占用问题,但对于一个纯英文小说,由于每个字母UTF-16最少也需要两个字节编码,相比于ASCII码仍然需要多占用一倍的空间,而且不能完全兼容ASCII码。更为严重的是,对于所有的ASCII字符,在UTF-16编码中的高位字节都是0x00,而0x00在ASCII码中代表Null,这被C语言使用当做字符串的结尾标志,所以会导致无法正确解析。
UTF-8编码也是一种变长编码,但与UTF-16不同的是,UTF-8可以使用一个、两个、三个或四个字节来表示字符。对于所有的ASCII字符,使用ASCII编码和UTF-8编码,结果完全相同,这保证了UTF-8编码良好的兼容性。同时UTF-8编码是单字节码元,没有字节序的问题,也不再需要BOM来进行标记,虽然有时windows系统会添加0xEE 0xBB 0xBF来声明一个文件是UTF-8编码,但实际上这并没有必要。
UTF-8编码现在被广泛的应用到互联网中,95%以上的网页都是使用UTF-8进行编码。根据编码规则,对于单字节字符,第一位固定为0,后面7位对应字符的Unicode码点值,与ASCII码完全兼容,所以我们可以使用UTF-8编码直接打开ASCII码文件。而对于多字节字符,例如需要X个字节,我们将第一个字节的前X位设为1,第X+1位设为0,然后后面的所有字节的前两位都设为10,剩下的二进制位使用该字符的Unicode码点填充。如下表所示:
| Unicode码点范围 | UTF-8 编码 |
|---|---|
| 0000 0000 - 0000 007F | 0xxxxxxx |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
同样以汉字“𠮷"为例,其Unicode码点值为U+20BB7,根据上表,需要使用4个字节表示,0x20BB7的二进制是10 0000 1011 1011 0111,一共18位,根据编码规则,四个字节的UTF-8编码一共有21位需要填充,所以在前3位补0,也就是000 10 0000 1011 1011 0111。将这21位填充到对应的x位置上,得到其UTF-8编码的二进制表示是11110000 10100000 10101110 10110111,使用16进制表示就是0xF0 0xA0 0xAE 0xB7。
乱码的产生
上面说了这么多种的字符集和字符编码,也能基本理解乱码其实就是由于用了错误的编码解释了字节串导致的。那么现在来看一下一些常见的乱码产生的过程。
首先是“烫烫烫",在windows下,编译器在debug模式下会把未初始化的栈内存全部填充为0xCC,而在GBK编码下,两个0xCC就正好是中文烫的编码。
至于看txt小说时常遇到的锟斤拷,则是由于GBK编码和UTF-8编码的互相转换导致的。如果我们有一个中文小说文件,在保存为txt的时候使用的是GBK编码,但是另一个人重新打开的时候却使用了UTF-8编码,那肯定有很多字符不符合UTF-8编码的规则无法显示,这时系统就会使用�字符进行替代,其Unicode码点值为U+FFFD,对应的UTF-8编码是0xEF 0xBF 0xBD。这时如果这个人选择了继续以UTF-8编码保存文件,那么所有的�字符都以字节串0xEF 0xBF 0xBD进行了保存,而当我们重新使用GBK编码打开文件时,连续的两个�对应的字节串是0xEF 0xBF 0xBD 0xEF 0xBF 0xBD,在GBK编码中,每两个字节代表一个字符,而0xEF 0xBF就是汉字"锟",0xBD 0xEF就是汉字"斤",0xBF 0xBD就是汉字"拷",到这里,满屏幕的锟斤拷就产生了。
Comments 1 条评论
VScode 终端中文乱码,后面改gbk 或者 Unicode 才正常输出。